word2vec
标签:word2vec, ngram, nnlm, cbow, c-skip-gram, 统计语言模型目录
- 1. 统计语言模型
- 2. CBOW(Continuous Bag-of-Words)
- 3. Continuous skip-gram
- 4. NCE
- 5. 面试常见问题
- x. tensorflow的简单实现
- y1. tensorflow的高级实现1
- y2. tensorflow的高级实现2
参考cdsn博客:http://blog.csdn.net/zhaoxinfan/article/details/27352659
参考paddlepaddle book: https://github.com/PaddlePaddle/book/blob/develop/04.word2vec/README.cn.md
参考fasttext及更多cbow/skip-gram:https://daiwk.github.io/posts/nlp-fasttext.html
Word2vec的原理主要涉及到统计语言模型(包括N-gram模型和神经网络语言模型(nnlm)),continuous bag-of-words模型以及continuous skip-gram模型。
语言模型旨在为语句的联合概率函数\(P(w_1,...,w_T)\)建模。语言模型的目标是,希望模型对有意义的句子赋予大概率,对没意义的句子赋予小概率。 常用条件概率表示语言模型:
\[
P(w_1, ..., w_T) = \prod_{t=1}^TP(w_t | w_1, ... , w_{t-1})
\]
1. 统计语言模型
N-gram模型
n-gram是一种重要的文本表示方法,表示一个文本中连续的n个项。基于具体的应用场景,每一项可以是一个字母、单词或者音节。一般用每个n-gram的历史n-1个词语组成的内容来预测第n个词。
神经网络语言模型(NNLM)
Yoshua Bengio等科学家就于2003年在著名论文 Neural Probabilistic Language Models中介绍如何学习一个神经元网络表示的词向量模型。神经概率语言模型(Neural Network Language Model,NNLM)通过一个线性映射和一个非线性隐层连接,同时学习了语言模型和词向量,即通过学习大量语料得到词语的向量表达,通过这些向量得到整个句子的概率。用这种方法学习语言模型可以克服维度灾难(curse of dimensionality),即训练和测试数据不同导致的模型不准。
实际上越远的词语其实对该词的影响越小,那么如果考虑一个n-gram, 每个词都只受其前面n-1个词的影响,则有:
\[
P(w_1, ..., w_T) = \prod_{t=n}^TP(w_t|w_{t-1}, w_{t-2}, ..., w_{t-n+1})
\]
给定一些真实语料,这些语料中都是有意义的句子,N-gram模型的优化目标则是最大化目标函数:
\[
\frac{1}{T}\sum_t f(w_t, w_{t-1}, ..., w_{t-n+1};\theta) + R(\theta)
\]
其中,\(f(w_t, w_{t-1}, ..., w_{t-n+1})\)表示根据历史n-1个词得到当前词\(w_t\)的条件概率,\(R(\theta)\)表示参数正则项。
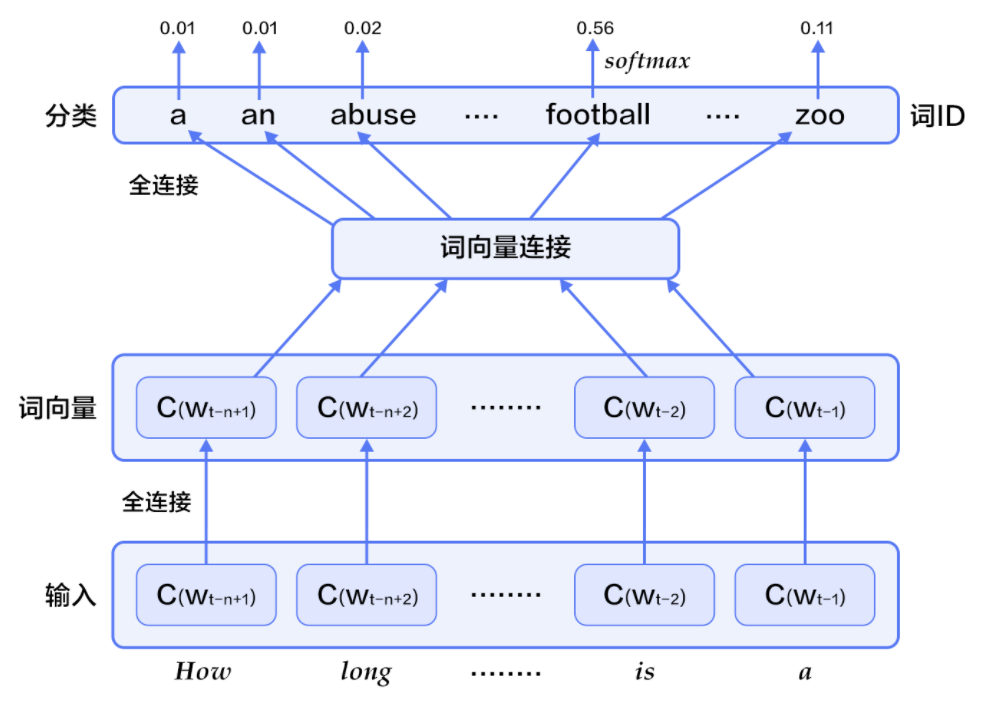
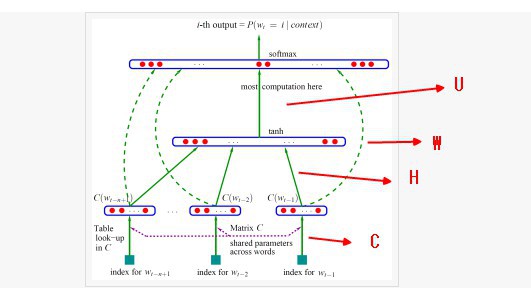
-
对于每个样本,模型输入
\(w_{t-n+1},...w_{t-1}\),输出句子第t个词为字典中\(|V|\)个词的概率。每个输入词\(w_{t-n+1},...w_{t-1}\)通过矩阵\(C\)映射到词向量\(C(w_{t-n+1}),...C(w_{t-1})\) -
然后所有词语的词向量连接成一个大向量,并经过一个非线性映射得到历史词语的隐层表示:
\[
g=Utanh(\theta^Tx + b_1) + Wx + b_2
\]
其中,x为所有词语的词向量连接成的大向量,表示文本历史特征;\(g\)表示未经归一化的所有输出单词概率,\(g_i\)表示未经归一化的字典中第i个单词的输出概率。其他参数为词向量层到隐层连接的参数。
- 根据softmax的定义,通过归一化
\(g_i\), 生成目标词\(w_t\)的概率为:
\[
P(w_t | w_1, ..., w_{t-n+1}) = \frac{e^{g_{w_t}}}{\sum_i^{|V|} e^{g_i}}
\]
- 整个网络的损失值(cost)为多类分类交叉熵,用公式表示为:
\[
J(\theta) = -\sum_{i=1}^N\sum_{c=1}^{|V|}y_k^{i}log(softmax(g_k^i))
\]
其中\(y_k^i\)表示第i个样本第k类的真实标签(0或1),\(softmax(g_k^i)\)表示第i个样本第k类softmax输出的概率。
2. CBOW(Continuous Bag-of-Words)
CBOW模型通过一个词的上下文(各N个词)预测当前词。当N=2时,模型如下图所示:
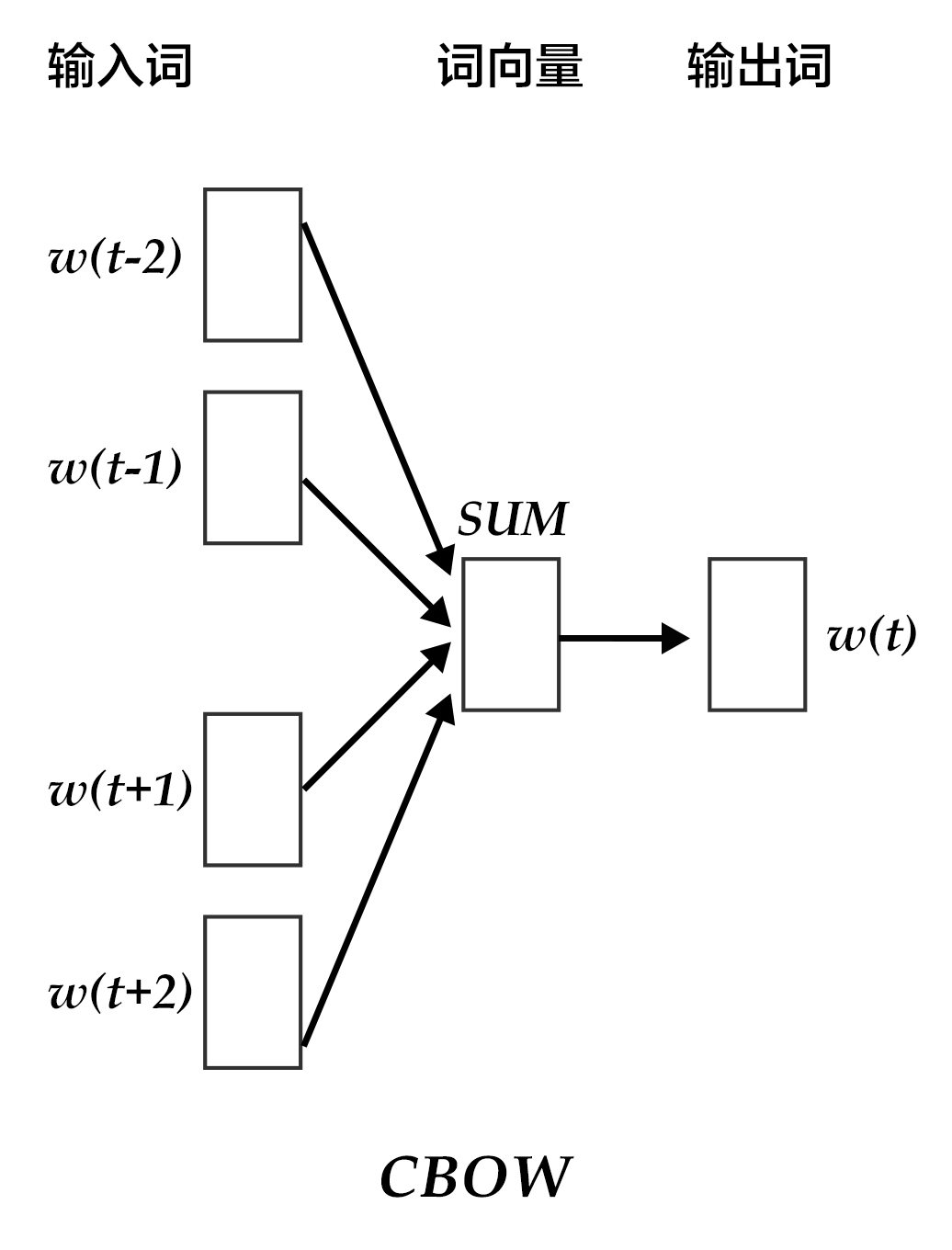
具体来说,不考虑上下文的词语输入顺序,CBOW是用上下文词语的词向量的均值来预测当前词。即:
\[
context = \frac{x_{t-1} + x_{t-2} + x_{t+1} + x_{t+2}}{4}
\]
其中\(x_t\)为第t个词的词向量,分类分数(score)向量 \(z=U*context\),最终的分类y采用softmax,损失函数采用多类分类交叉熵。
CBOW经常结合hierarchical softmax一起实现,详见https://daiwk.github.io/posts/nlp-fasttext.html#02-%E5%88%86%E5%B1%82softmax
3. Continuous skip-gram
CBOW的好处是对上下文词语的分布在词向量上进行了平滑,去掉了噪声,因此在小数据集上很有效。而Skip-gram的方法中,用一个词预测其上下文,得到了当前词上下文的很多样本,因此可用于更大的数据集。
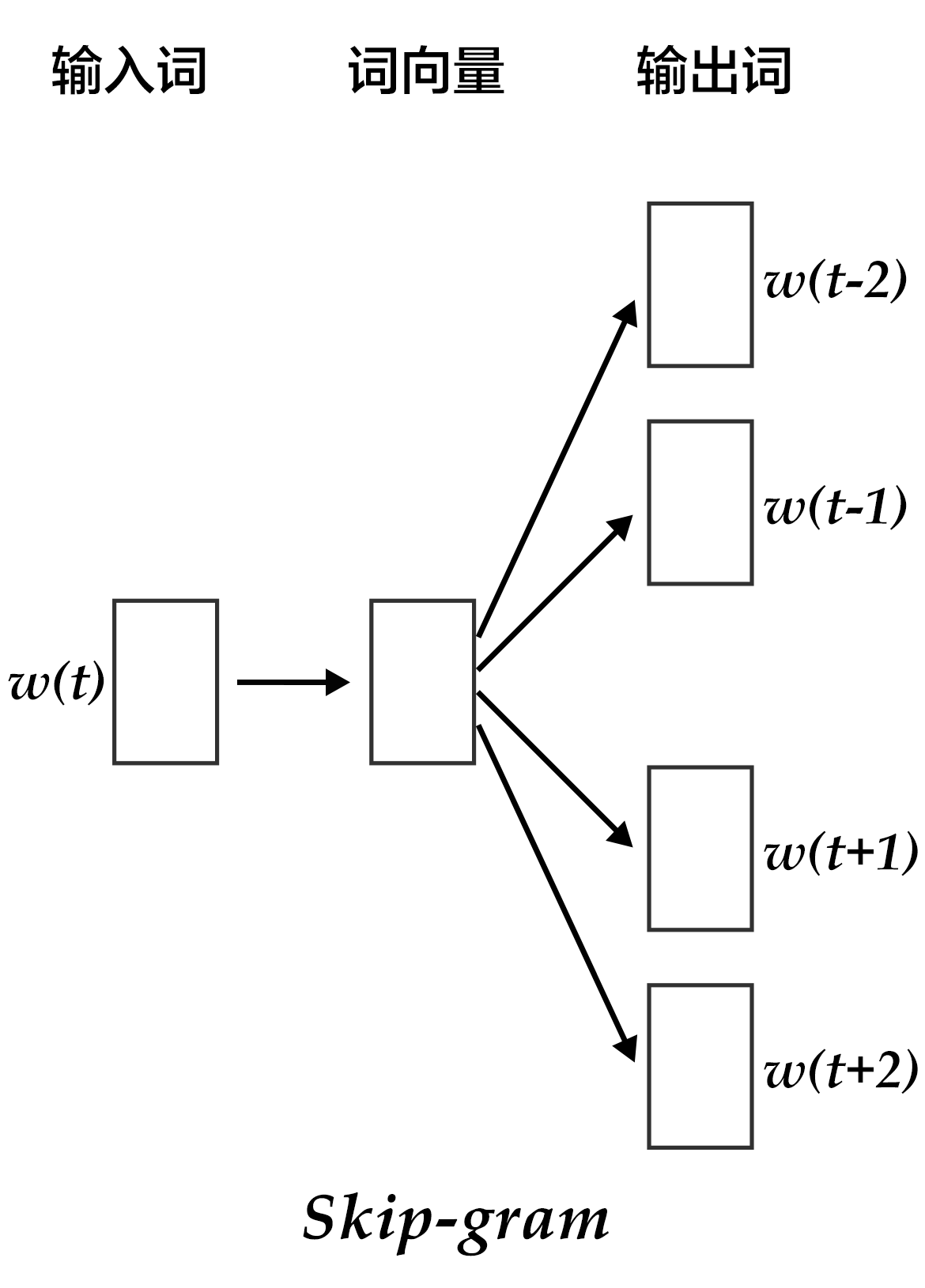
如上图所示,Skip-gram模型的具体做法是,将一个词的词向量映射到2n个词的词向量(2n表示当前输入词的前后各n个词),然后分别通过softmax得到这2n个词的分类损失值之和。
参考https://blog.csdn.net/u014595019/article/details/54093161
『我当时使用的是Hierarchical Softmax+CBOW的模型。给我的感觉是比较累,既要费力去写huffman树,还要自己写计算梯度的代码,完了按层softmax速度还慢。这次我决定用tensorflow来写,除了极大的精简了代码以外,可以使用gpu对运算进行加速。此外,这次使用了负采样(negative sampling)+skip-gram模型,从而避免了使用Huffman树导致训练速度变慢的情况,适合大规模的文本。』
而且,在tf中的实现tensorflow/tensorflow/examples/tutorials/word2vec/word2vec_basic.py,也是基于skip-gram+nce_loss的。
4. NCE
参考https://blog.csdn.net/itplus/article/details/37998797
5. 面试常见问题
参考 https://blog.csdn.net/zhangxb35/article/details/74716245
x. tensorflow的简单实现
讲解:https://www.tensorflow.org/tutorials/word2vec
简介
使用maximum likelihood principle,最大化给定previous words \(h\),下一个词\(w_t\)的概率(使用softmax定义):
\[
\begin{align}
P(w_t | h) &= \text{softmax} (\text{score} (w_t, h)) \\
&= \frac{\exp \{ \text{score} (w_t, h) \} }
{\sum_\text{Word w' in Vocab} \exp \{ \text{score} (w', h) \} }
\end{align}
\]
需要最大化的对应的log-likelihood就是:
\[
\begin{align}
J_\text{ML} &= \log P(w_t | h) \\
&= \text{score} (w_t, h) -
\log \left( \sum_\text{Word w' in Vocab} \exp \{ \text{score} (w', h) \} \right).
\end{align}
\]
如果直接硬算,对于每个时间步,都需要遍历词典大小的空间,显然效率是不行的。在word2vec中,将这样一个多分类问题,变成了一个区分目标词\(w_t\)和k个noise words\(\tilde w\)的二分类问题。下图是cbow的示例,skipgram正好是倒过来。
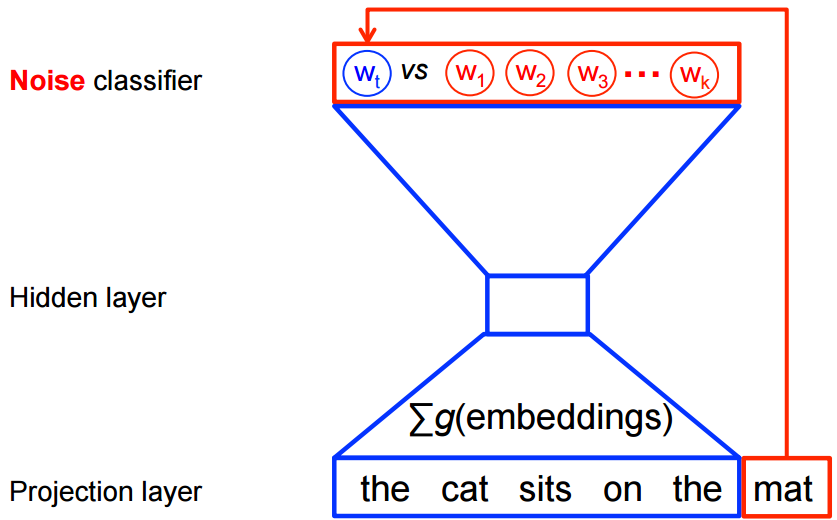
数学上,目标就是要最大化:
\[
J_\text{NEG} = \log Q_\theta(D=1 |w_t, h) +
k \mathop{\mathbb{E}}_{\tilde w \sim P_\text{noise}}
\left[ \log Q_\theta(D = 0 |\tilde w, h) \right]
\]
其中,\(Q_\theta(D=1 | w, h)\)是使用学到的embedding vector \(\theta\),在给定上下文h,预测词w的概率。
直观地理解,这个目标就是希望预测为\(w_t\)的概率尽可能大,同时预测为非\(\tilde w\)的概率尽可能大,也就是,希望预测为真实词的概率尽量大,预测为noise word的概率尽量小。在极限情况下,这可以近似为softmax,但这计算量比softmax小很多。这就是所谓的negative sampling。tensorflow有一个很类似的损失函数noise-contrastive estimation(NCE)tf.nn.nce_loss()。
针对句子
the quick brown fox jumped over the lazy dog
如果使用window_size=1,那么对于CBOW,就有:
([the, brown], quick), ([quick, fox], brown), ([brown, jumped], fox), ...
而对于skipgram,则有:
(quick, the), (quick, brown), (brown, quick), (brown, fox), ...
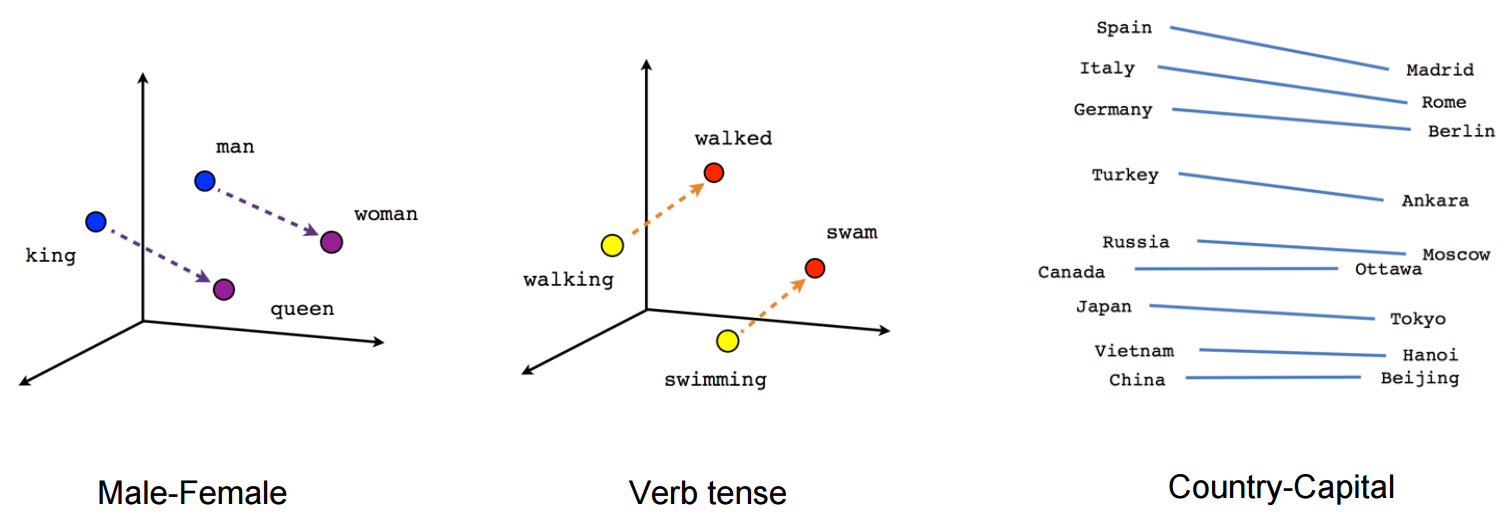
画图时,可以使用t-SNE的降维方法,将高维向量映射到2维空间。
代码解读
首先build一个dataset:
def build_dataset(words, n_words):
"""Process raw inputs into a dataset."""
count = [['UNK', -1]]
count.extend(collections.Counter(words).most_common(n_words - 1)) ## 取出词频top n_words-1的词,词频高的index小
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
data = list()
unk_count = 0
for word in words:
index = dictionary.get(word, 0)
if index == 0: # dictionary['UNK']
unk_count += 1
data.append(index)
count[0][1] = unk_count
reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reversed_dictionary
而在NCE的实现中,使用的是log_uniform_candidate_sampler:
- 会在[0, range_max)中采样出一个整数k
- P(k) = (log(k + 2) - log(k + 1)) / log(range_max + 1)
k越大,被采样到的概率越小。而我们的词典中,可以发现词频高的index小,所以高词频的词会被优先采样为负样本。
其中的生成一个batch的方法如下:
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1 # [ skip_window target skip_window ]
buffer = collections.deque(maxlen=span) # pylint: disable=redefined-builtin
if data_index + span > len(data):
data_index = 0
buffer.extend(data[data_index:data_index + span])
data_index += span
for i in range(batch_size // num_skips):
context_words = [w for w in range(span) if w != skip_window]
words_to_use = random.sample(context_words, num_skips)
for j, context_word in enumerate(words_to_use):
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[context_word]
if data_index == len(data):
buffer.extend(data[0:span])
data_index = span
else:
buffer.append(data[data_index])
data_index += 1
# Backtrack a little bit to avoid skipping words in the end of a batch
data_index = (data_index + len(data) - span) % len(data)
return batch, labels
y1. tensorflow的高级实现1
https://github.com/tensorflow/models/blob/master/tutorials/embedding/word2vec.py
y2. tensorflow的高级实现2
https://github.com/tensorflow/models/blob/master/tutorials/embedding/word2vec_optimized.py